Blog
Articles about computational science and data science, neuroscience, and open source solutions. Personal stories are filed under Weekend Stories. Browse all topics here. All posts are CC BY-NC-SA licensed unless otherwise stated. Feel free to share, remix, and adapt the content as long as you give appropriate credit and distribute your contributions under the same license.
tags · RSS · Mastodon · simple view · page 5/20
Nullclines and fixed points of the Rössler attractor
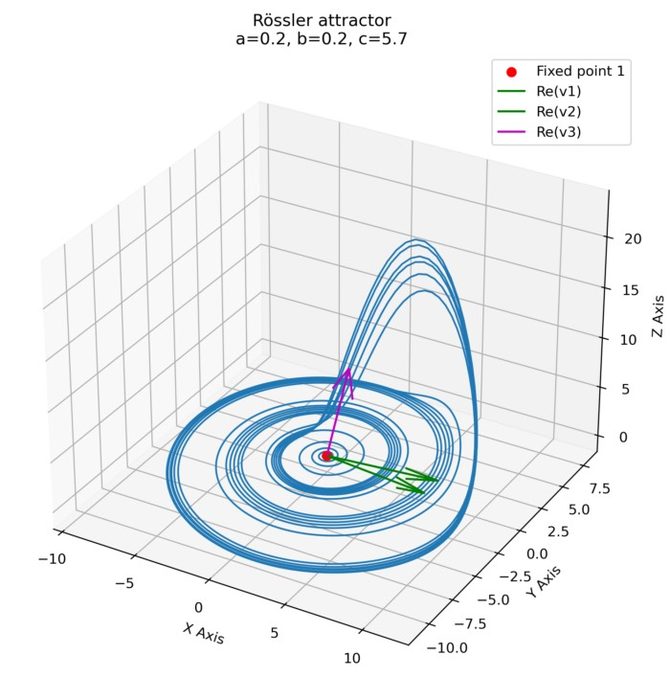
After introducing phase plane analysis in the previous post, we will now apply this method to the Rössler attractor presented earlier. We will investigate the system’s nullclines and fixed points, and analyze the attractor’s dynamics in the phase space.
Using phase plane analysis to understand dynamical systems

When it comes to understanding the behavior of dynamical systems, it can quickly become too complex to analyze the system’s behavior directly from its differential equations. In such cases, phase plane analysis can be a powerful tool to gain insights into the system’s behavior. This method allows us to visualize the system’s dynamics in phase portraits, providing a clear and intuitive representation of the system’s behavior. Here, we explore how we can use this method and exemplarily apply it to the simple pendulum.
PyTorch on Apple Silicon

Already some time ago, PyTorch became fully available for Apple Silicon. It’s no longer necessary to install the nightly builds to run PyTorch on the GPU of your Apple Silicon machine as I described in one of my earlier posts.
Rössler attractor
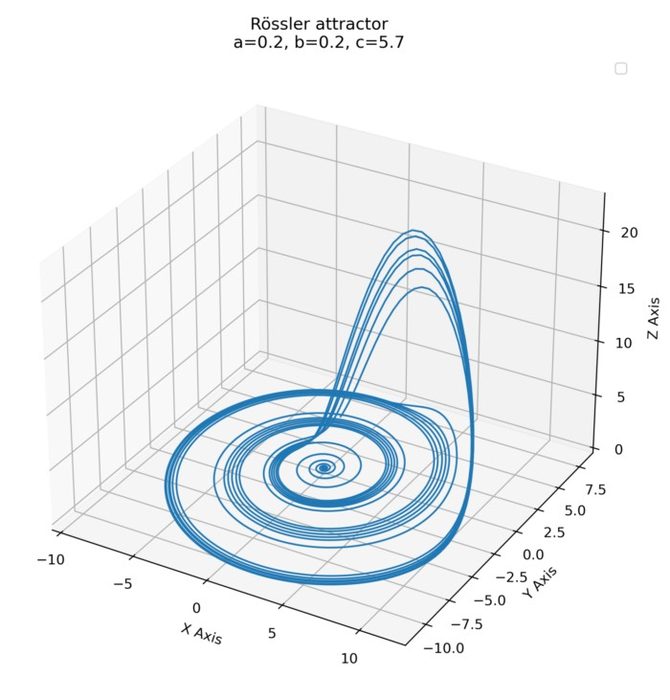
Unlike the Lorenz attractor which emerges from the dynamics of convection rolls, the Rössler attractor does not describe a physical system found in nature. Instead, it is a mathematical construction designed to illustrate and study the behavior of chaotic systems in a simpler, more accessible manner. In this post, we explore how we can quickly simulate this strange attractor using simple Python code.
Understanding Hebbian learning in Hopfield networks

Hopfield networks, a form of recurrent neural network (RNN), serve as a fundamental model for understanding associative memory and pattern recognition in computational neuroscience. Central to the operation of Hopfield networks is the Hebbian learning rule, an idea encapsulated by the maxim ‘neurons that fire together, wire together’. In this post, we explore the mathematical underpinnings of Hebbian learning within Hopfield networks, emphasizing its role in pattern recognition.
Building a neural network from scratch using NumPy

Ever thought about building you own neural network from scratch by simply using NumPy? In this post, we will do exactly that. We will build, from scratch, a simple feedforward neural network and train it on the MNIST dataset.
Python’s version logos
Have you ever noticed that Python has introduced individual version logos starting with version 3.10? I couldn’t find any official announcement, but luckily, the Python community on Mastodon was able to help out.

Conditional GANs

I was wondering whether it would be possible to let GANs generate samples conditioned on a specific input type. I wanted the GAN to generate samples of a specific digit, resembling a personal poor man’s mini DALL•E. And indeed, I found a GAN architecture, that allows what I was looking for: Conditional GANs.
Eliminating the middleman: Direct Wasserstein distance computation in WGANs without discriminator
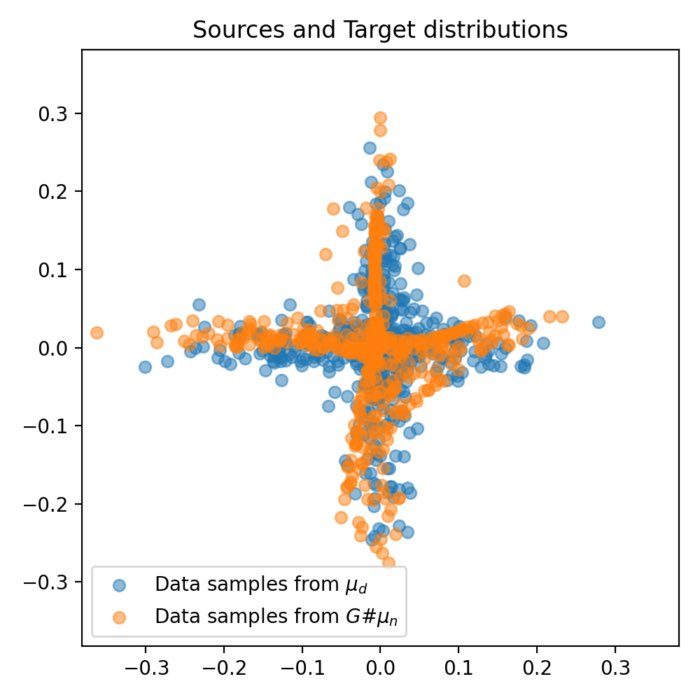
We explore an alternative approach to implementing WGANs. Contrasting from the standard implementation that requires both a generator and discriminator, the method discussed here employs the optimal transport to compute the Wasserstein distance directly between the real and generated data distributions, eliminating the need for a discriminator.