Blog
Articles about computational science and data science, neuroscience, and open source solutions. Personal stories are filed under Weekend Stories. Browse all topics here. All posts are CC BY-NC-SA licensed unless otherwise stated. Feel free to share, remix, and adapt the content as long as you give appropriate credit and distribute your contributions under the same license.
tags · RSS · Mastodon · simple view · page 6/20

Conditional GANs

I was wondering whether it would be possible to let GANs generate samples conditioned on a specific input type. I wanted the GAN to generate samples of a specific digit, resembling a personal poor man’s mini DALL•E. And indeed, I found a GAN architecture, that allows what I was looking for: Conditional GANs.
Eliminating the middleman: Direct Wasserstein distance computation in WGANs without discriminator
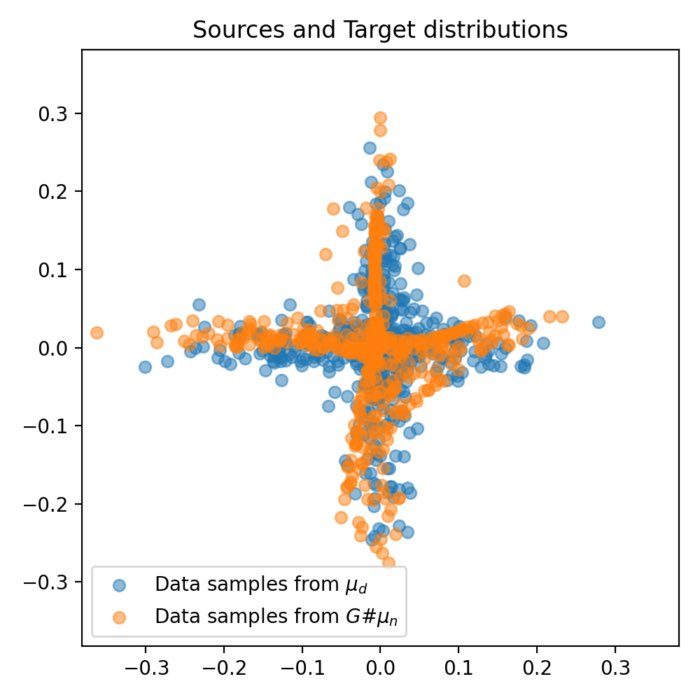
We explore an alternative approach to implementing WGANs. Contrasting from the standard implementation that requires both a generator and discriminator, the method discussed here employs the optimal transport to compute the Wasserstein distance directly between the real and generated data distributions, eliminating the need for a discriminator.
Wasserstein GANs
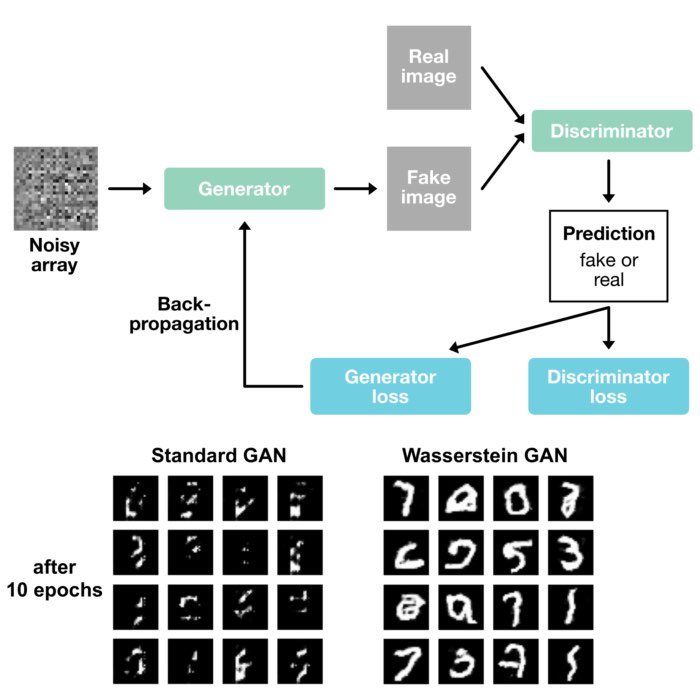
We apply the Wasserstein distance to Generative Adversarial Networks (GANs) to train them more effectively. We compare a default GAN with a Wasserstein GAN (WGAN) trained on the MNIST dataset and discuss the advantages and disadvantages of both approaches.
Probability distance metrics in machine learning
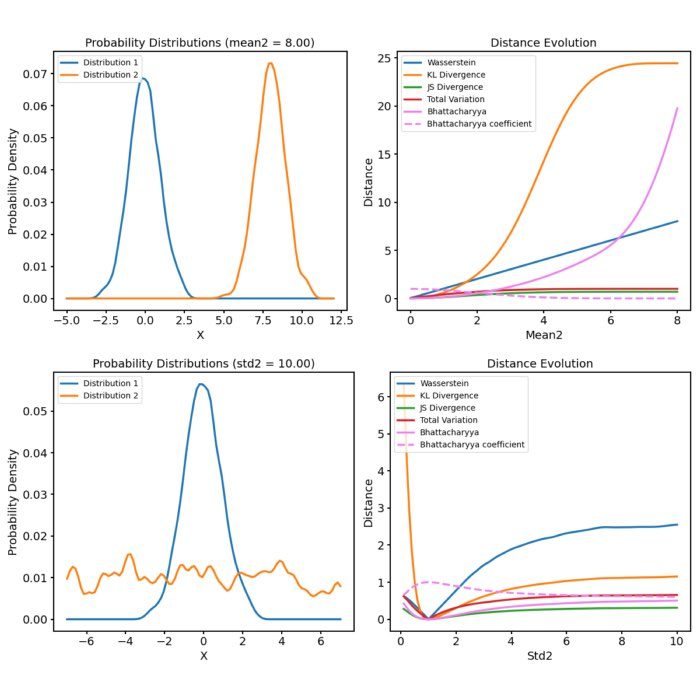
Probabilistic distance metrics play a crucial role in a broad range of machine learning tasks, including clustering, classification, and information retrieval. The choice of metric is often determined by the specific requirements of the task at hand, with each having unique strengths and characteristics. In this post, we discuss five commonly used metrics: the Wasserstein Distance, the Kullback-Leibler Divergence (KL Divergence), the Jensen-Shannon Divergence (JS Divergence), the Total Variation Distance (TV Distance), and the Bhattacharyya Distance.
Comparing Wasserstein distance, sliced Wasserstein distance, and L2 norm
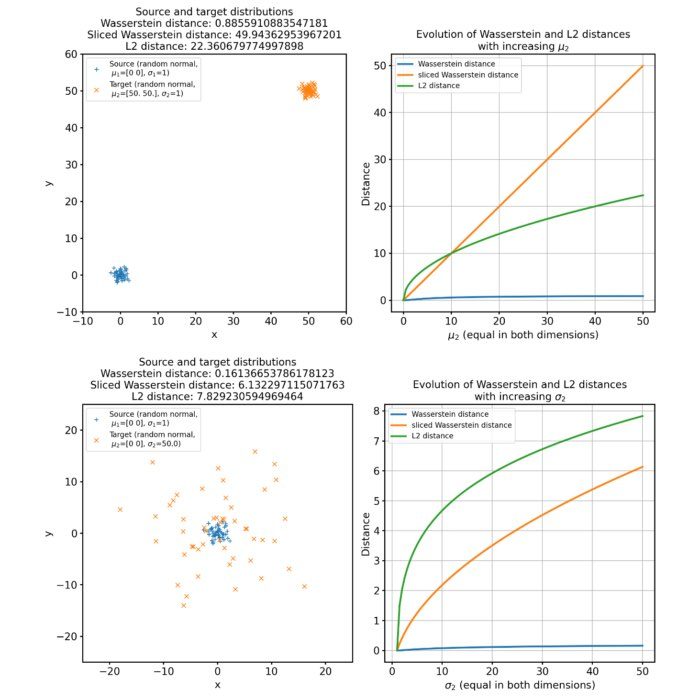
In machine learning, especially when dealing with probability distributions or deep generative models, different metrics are used to quantify the ‘distance’ between two distributions. Among these, the Wasserstein distance (EMD), sliced Wasserstein distance (SWD), and the L2 norm, play an important role. Here, we compare these metrics and discuss their advantages and disadvantages.
Approximating the Wasserstein distance with cumulative distribution functions
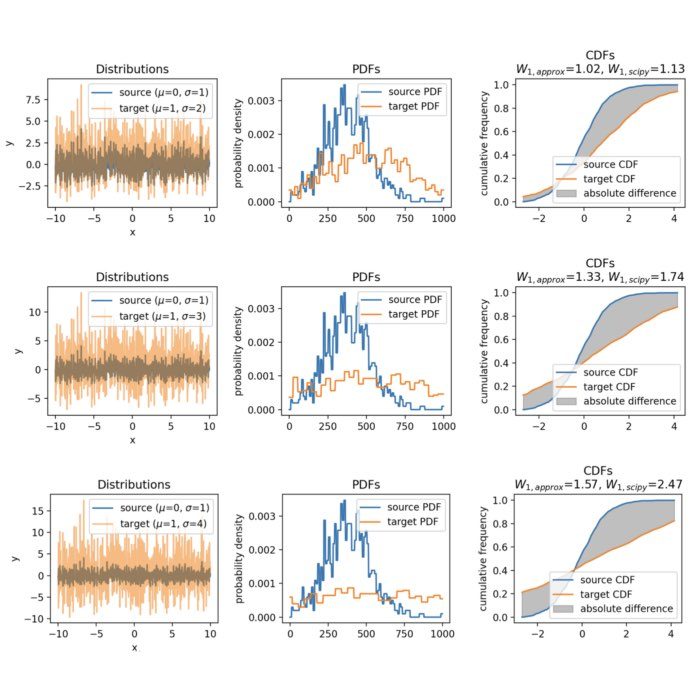
In the previous two posts, we’ve discussed the mathematical details of the Wasserstein distance, exploring its formal definition, its computation through linear programming and the Sinkhorn algorithm. In this post, we take a different approach by approximating the Wasserstein distance with cumulative distribution functions (CDF), providing a more intuitive understanding of the metric.
Wasserstein distance via entropy regularization (Sinkhorn algorithm)
Calculating the Wasserstein distance can be computational costly when using linear programming. The Sinkhorn algorithm provides a computationally efficient method for approximating the Wasserstein distance, making it a practical choice for many applications, especially for large datasets.
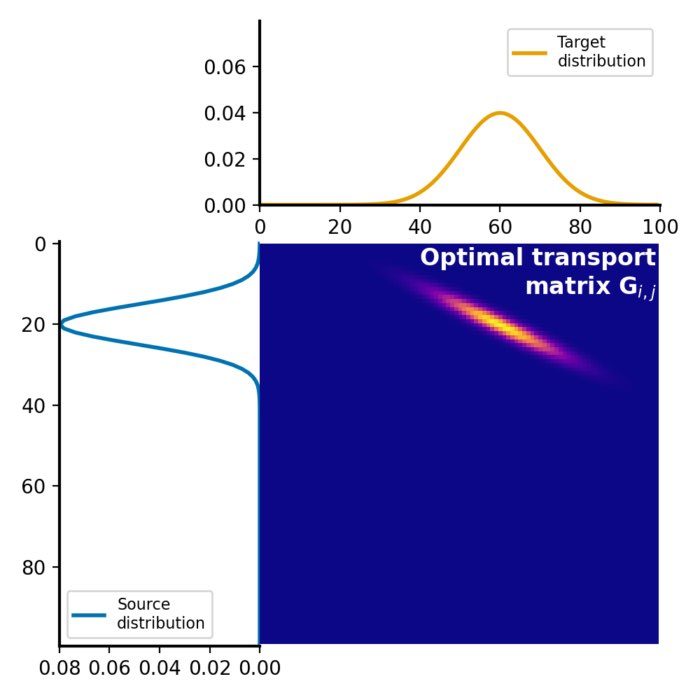
Wasserstein distance and optimal transport
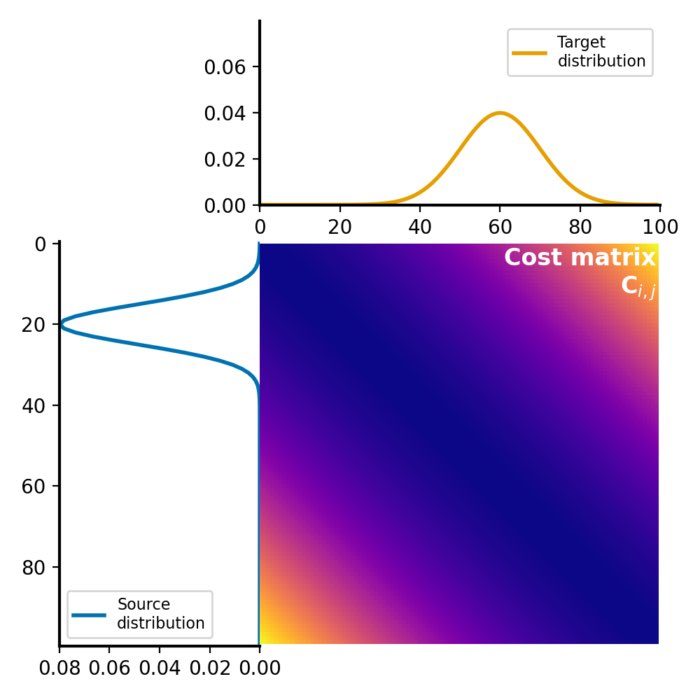
The Wasserstein distance, also known as the Earth Mover’s Distance (EMD), provides a robust and insightful approach for comparing probability distributions and finds application in various fields such as machine learning, data science, image processing, and information theory. In this post, we take a look at the optimal transport problem, required to calculate the Wasserstein distance, and how to calculate the distance metric in Python.
Visualizing Occam’s Razor through machine learning
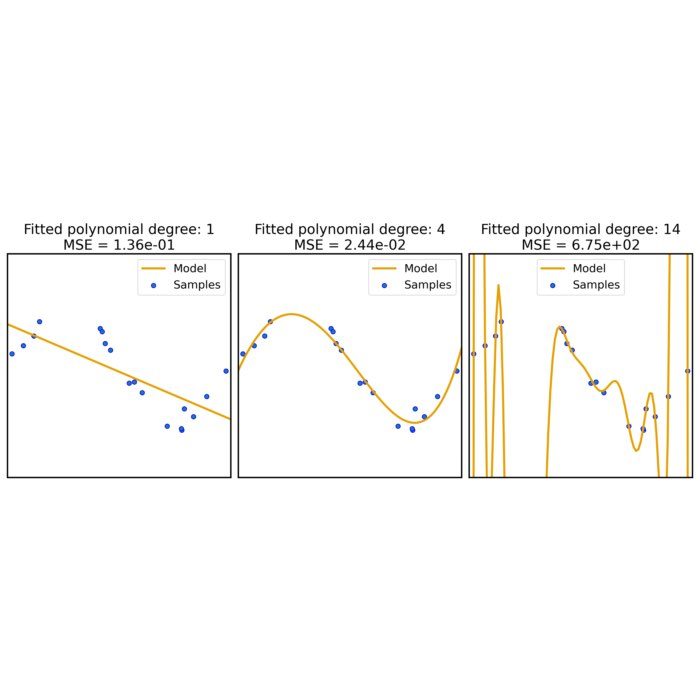
Here, we illustrate the concept of Occam’s Razor, a principle advocating for simplicity, by examining its manifestation in the domain of machine learning using Python.