Python data I/O Cheat Sheet
This Cheat Sheet is a collection of common Python data I/O functions.
Built-in Python I/O functions
Python’s built-in I/O function can handle two types of files: normal text files and binary files.
Open and/or create a file with open():
filename = 'my_data_file.txt'
file_object = open(filename, mode='r') # open a file
text = file_object.read() # reading file content and
# saving it into a variable
file_object.close() # closes the open file
# (always necessary!)
print(text) # show file content
The mode variable defines how your file will be opened. Available modes are:
| mode | description |
|---|---|
r |
read-only mode (default), reading from the beginning of the file, raise error if file does not exist |
r+ |
read-and-write mode, reading from the beginning of the file, raise error if file does not exist |
w |
write-only mode, will overwrite any existing file with the same name, creates a new file if one with the same name doesn’t exist |
w+ |
read-and-write mode, reading from the beginning of the file, will overwrite any existing file with the same name, creates a new file if one with the same name doesn’t exist |
a |
opens a file for appending new entries at the end of an existing file (i.e., after and existing data), creates a new file if one with the same name doesn’t exist |
a+ |
opens a file for both appending and reading, creates a new file if one with the same name doesn’t exist, new entries will be appended at the end of the file |
You can check whether your file is still open or not via:
print(file_object.closed)
File handle: The files are opened or created with an internal file handle. The file handle is like a pointer, which defines from where the data will be read or written in the file.
Write to a new or existing file with write():
file_object = open(filename, mode='w+')
entry = "a word"
file_object.write("entry") # inserts a new entry in a single
# line in the text file.
L = ["word 1\n", "word 2\n", "word 3\n"]
file_object.writelines(L) # inserts a list of entries at
# a single time; "\n" forces a
# line after each entry in L
file_object.close()
Read from an exiting file with read(), readline() and readlines():
file_object = open(filename, mode='r')
print(file_object.read()) # reads all lines of the file and puts
# the current handle at the end of the
# file
file_object.seek(0) # rewinds the file and puts the current
# handle at the beginning of the file
N_lines = len(file_object.readlines()) # get the number of line within the
file_object.seek(0) # file
for line in range(N_lines):
print(file_object.readline()) # reads one line at the current handle
# and puts the handle to the next line
file_object.seek(0)
print(file_object.readlines()) # reads all lines at once, stores them
# in a list and puts the handle at
# the file
file_object.close()
Of course, you can read from a file and store the read entries into a variable:
file_object = open(filename, mode='r')
# by looping over individual lines:
my_data_list = []
N_lines = len(file_object.readlines())
file_object.seek(0)
for line in range(N_lines):
my_data_list.append(file_object.readline())
file_object.seek(0)
# or via the readlines() command:
my_data_list2 = file_object.readlines()
file_object.close()
NumPy I/O functions
The following table contains the most common NumPy data I/O functions:
| command | description | command | description |
|---|---|---|---|
np.save()ꜛ |
write an array to a binary npy ꜛ file |
np.load()ꜛ |
load arrays or pickled objects from .npy/.npzꜛ or pickledꜛ files |
np.savetxt()ꜛ |
write an array to a text file | np.loadtxt() ꜛ |
load data from a text file of one data type |
np.genfromtxt() ꜛ |
load data from a text file of mixed data type |
Examples:
import numpy as np
array_2D = np.random.random((20,2))
# save and load a binary npy-file:
filename_npy = "my_array.npy"
np.save(filename_npy, array_2D)
array_2D_from_file_npy = np.load(filename_npy)
print(array_2D_from_file_npy)
# save and load a human-readable txt-file for arrays of one data type:
filename_csv = "my_array.csv"
np.savetxt(filename_csv, array_2D, delimiter=", ")
array_2D_from_file_csv = np.loadtxt(filename_csv, delimiter=", ",
skiprows=0, dtype=float)
print(array_2D_from_file_csv)
# load a human-readable txt-file for arrays of mixed data type:
array_2D_from_file_csv = np.genfromtxt(filename_csv, delimiter=", ",
names=True, #Look for column header)
print(array_2D_from_file_csv)
Note, while the np.savetxt() ꜛ command creates human-readable text files, the np.save() ꜛ creates so-called npy ꜛ files. These files can not be read, e.g., by standard test editors. However, they bring some advantages:
- NumPy arrays are saved with the full information to reconstruct them including shape and dtype on a machine of a different architecture
npyist straightforward to reverse engineer, e.g., to reconstruct anpyreader if the program, with which the file was created, does longer not exist- allows memory-mapping ꜛ of the data
Note: A full overview of available NumPy I/O functions can be found on the Numpy documentation website ꜛ.
Pandas I/O functions
The following table contains the most common Pandas data I/O functions:
| command | description | command | description |
|---|---|---|---|
DataFrame.to_excel()ꜛ |
write DataFrame to an Excel sheet | pd.read_excel()ꜛ |
write an Excel sheet into DataFrame |
DataFrame.to_csv()ꜛ |
write DataFrame to a CSV file | pd.read_csv() ꜛ |
read a CSV file into DataFrame |
DataFrame.to_hdf()ꜛ |
write DataFrame to an HDFꜛ store | pd.read_hdf() ꜛ |
read DataFrame from an HDFꜛ store |
DataFrame.to_pickle()ꜛ |
pickleꜛ (serialize) DataFrame to file. | pd.read_pickle()ꜛ |
load pickled Pandas object (or any object) from file |
Examples:
import pandas as pd
import numpy as np
array_2D = np.random.random((20,2))
df = pd.DataFrame(data=array_2D, columns=["Column 1", "Column 2"])
# saving a Pandas DataFrame to file:
df.to_excel("my_array.xlsx")
df.to_csv("my_array.csv", mode="w")
df.to_hdf("my_array.h5", key='df', mode="w")
df.to_pickle("my_array.pkl")
# loading a Pandas DataFrame from file:
df_read = pd.read_excel("my_array.xlsx")
df_read = pd.read_csv("my_array.csv", mode="w")
df_read = pd.read_hdf("my_array.h5")
df_read = pd.read_pickle("my_array.pkl")
Note: A full overview of available Pandas I/O functions can be found on the Pandas documentation website ꜛ.
MATLAB files
import scipy.io
filename = 'workspace.mat'
mat = scipy.io.loadmat(filename)
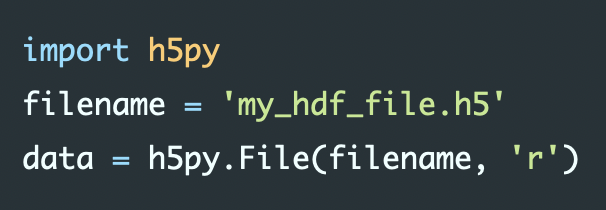
HDF5 files
import h5py
filename = 'my_hdf_file.h5'
data = h5py.File(filename, 'r')
Pickled files
https://docs.python.org/3/library/pickle.html ꜛ
import pickle
with open('pickled_data_file.pkl', 'rb') as file:
pickled_data = pickle.load(file)